











#008: CAM - Code Action Model: An Intelligent Code Generation & Testing Agent
Authors: Anand Natarajan, Director of Solutions Delivery @ xLM ContinuousLabs
Project Mayacode @ xLM Continuous Labs
Goal: This project aims to develop a GenAI Framework. The purpose of this framework is to automate code generation and comprehensive validation. The focus is on code related to rules governing data acquisition in Electronic Data Capture (EDC) within Clinical Data Management (CDMS).
Context: Clinical Data Management (CDMS) is the process of collecting, cleaning, and managing clinical trial data in compliance with regulatory standards. The primary objective of CDMS processes is to ensure data accuracy, adherence to protocols, and suitability for statistical analysis. Clinical Data Management Systems (CDMS) are used to capture data for clinical trials.
A study translates protocol specific activities into generated data. A study is essentially a road map to handle the data under foreseeable circumstances and describes the CDM activities to be followed in the trial.
Concomitant to study design is the definition of rules. Rules play a crucial role in collecting, validating, and identifying discrepancies in trial data. For instance, if the screening criterion for a subject (rule) stipulates that the ECG (Electrocardiogram) readings must be taken within 15 minutes of the collection of vital signs, code will be written for checking those conditions. If for any subject, the condition is not met, a discrepancy will be generated.
Rules can also dictate contextual data capture based on subject characteristics (e.g., gender, age, ethnicity). Additionally, rules guide users to relevant forms during clinical trial execution. In effect, rules drive the mechanics of data collection during clinical trials.
Use Case: During the design of a study, rules are defined in natural language. System developers then parse these rules and convert them into programmatic instructions with specific syntax. This process is manually intensive, requiring developers to be well-versed in study design, navigation paths, and programming rules. After converting rules to programmatic instructions, the crucial step is validating their correctness.
To achieve this, one must:
-
Execute the entire flow of the study, considering all possible navigation paths.
-
Test all permutations of scenario-based paths.
-
Ensure that all study-relevant rules are triggered and tested.
However, this validation process can be arduous and error prone.
Industry Need: A large cloud software company in the CDMS space, that provides services to over 1,000 life sciences companies, recognizes the need to reduce the time required for generating and validating rules associated with a study.
Outcome: Picture this.
Scenario:
-
Imagine a study designer faced with the task of defining rules for a clinical trial.
-
Instead of laboriously crafting these rules in technical jargon, they simply upload natural language descriptions via a chatbot.
- The GenAI Agent:
- Simulation and Validation
- The Grand Reveal
How does the Mayacode team make this possible?
Approach
With the advent of open-access and closed-source large language models (LLMs), the powers of deep learning from both structured and unstructured data have been unleashed. By combining LLMs with xLM’s proprietary core automation framework, Mayacode gains synergistic capabilities. This powerful combination enables Mayacode to offer a comprehensive solution.
The team took a pragmatic approach by starting with a simple POC. The goal was to assess the feasibility of a pared-down version of the solution. The team was galvanized after the results showed promise.
With a utopian goal of end-to-end automation, the xLM team aimed high. They deconstructed the envisioned solution into its foundational components/phases. Each component now has endpoints for seamless integration.
High-Level Architecture of Mayacode
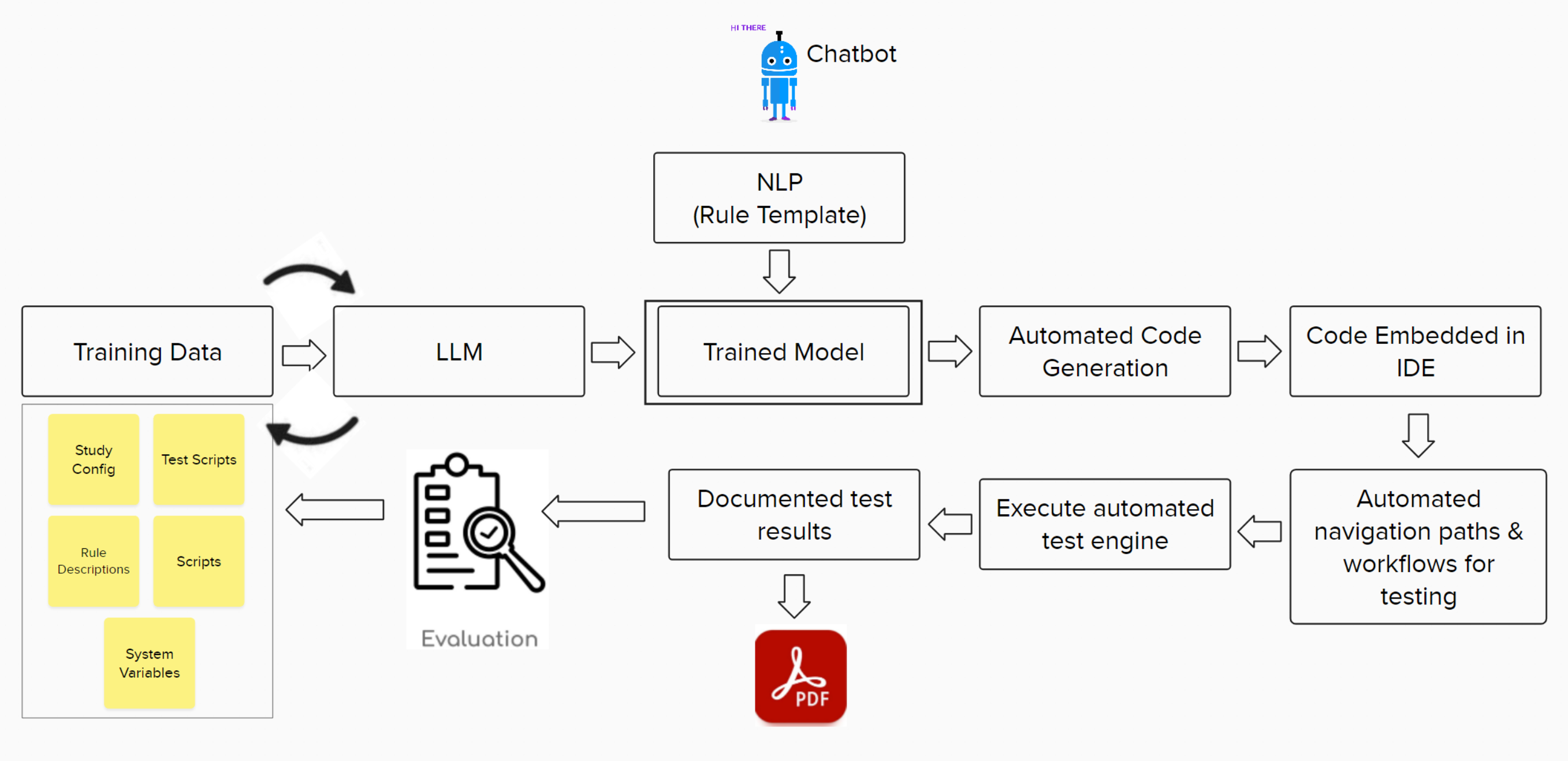
Figure 1: High-Level Approach/Architecture
#1 Ingest & Curate
In the context of Clinical Data Management Systems (CDMS), the study takes center stage.
-
Within a typical study, several critical components play crucial roles.
- Key Components of a Study
- Knowledge Base Essentials
- Ingestion and Training
This marks the ingestion and training phase—where magic happens.
In this intricate dance of data, Mayacode awakens, ready to transform complexity into clarity.
#2 Assess & Cultivate
The goal is to train the LLM to parse natural language rules, decipher navigation steps, and generate syntactically correct programmatic instructions. This process is standardized using a template for consistency and facilitated through a simple chat-based UI. The LLM’s learning capability and accuracy are evaluated due to the process’s complexity, and training is modulated and refined through Reinforced Learning Through Human Feedback (RLHF) to incrementally cultivate the desired level of accuracy.
#3 Generate & Automate
End-users can input rule descriptions individually or upload a file with all rules via an intuitive interface. The AI agent, using its training and knowledge base, generates code reflecting the rule’s intent and inserts it into an IDE using Robotic Process Automation (RPA). The agent, in association with xLM’s core automation framework, then validates rules by simulating trial execution in logical workflows, documenting results in a PDF, and indicating validation successes or failures. A platform for batch execution of test scripts was also established.
#4 Evaluate & Re-educate
Results from every execution are fed back to the agent so that gaps and inaccuracies can slowly be minimized and eradicated. Metrics related to this process are used to quantify the deviations from anticipated results and are used to gauge improvement in accuracy. As the agent continues to be exposed to varying studies, their nuances and unique scenarios, it begins to deepen and widen its knowledge base. This enhances the accuracy of the results produced and minimizes manual intervention and remediation.
Sample Outputs from Mayacode
Figure 2 below shows the output of the script generated by the AI agent based on natural language description of the rule.
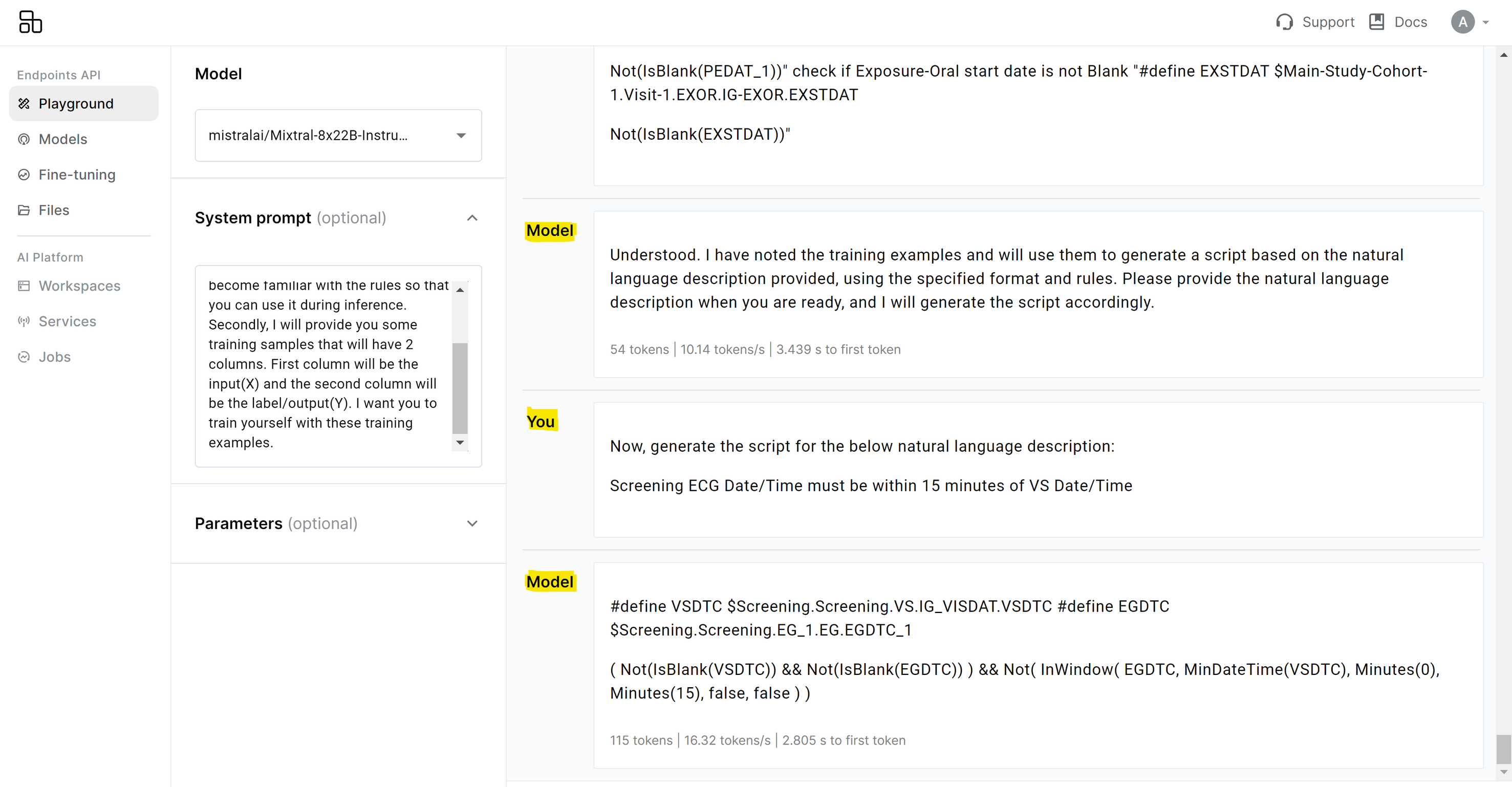
Figure 2: Script generated by agent
Figures 3 & 4 below show the PDF output generated from the automated validation.

Figure 3: Sample cover page of automated test output
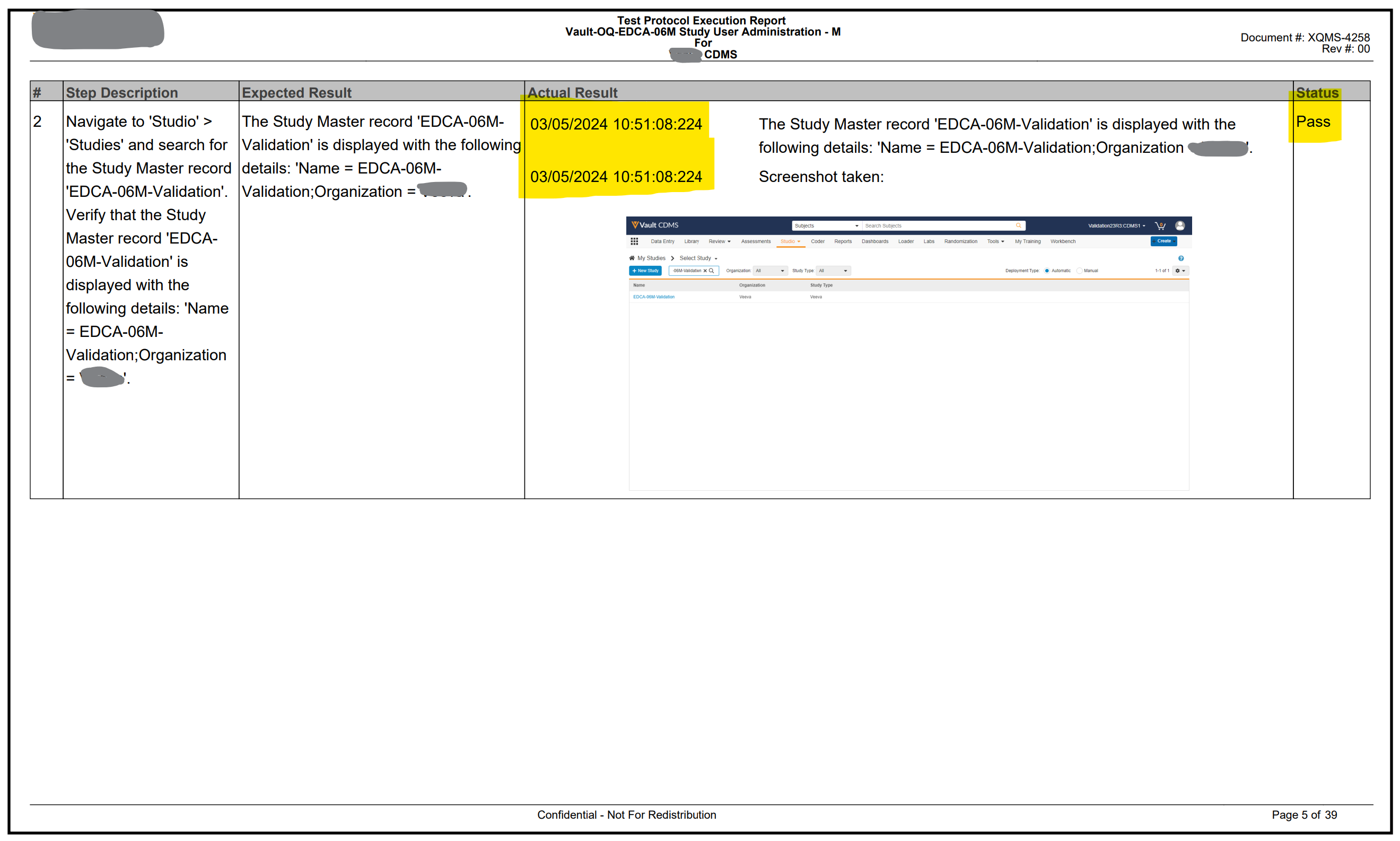
Figure 4: Sample output of test execution evidence
Conclusion
Experience a revolution in efficiency and cost savings with our CAM. Imagine the manual creation of 1000 rules. The manual script generation and validation process would take an average of 3 man-months. Now, enter Mayacode. With Mayacode, the time required to generate rule expressions and validate 1000 rules is reduced to a mere 5 hours. That’s an efficiency gain of an astounding 100X! And the cost savings? A minimum of $100,000!
But that’s not all. Mayacode’s user-friendly design means the CDMS application can be continuously validated. Re-validation and regression testing due to upgrades or changes become a walk in the park. This agent is set to redefine the way studies are designed and tested in the CDMS domain.
Looking ahead, we envision the introduction of the Model-in-the-Loop concept. A second model will perform all required checks and corrective actions, achieving end-to-end automation with unparalleled accuracy and speed. The future of efficiency is here with Mayacode.
Watch this edition on YouTubeListen to this edition on Spotify
What questions do you have about artificial intelligence in Life sciences? No question is too big or too small. Submit your questions about AI via this survey here.

COMMENTS